
Some Background
In our July 2021 blog, “Cloud.Work.Flow” we listed several gaps which will need to be closed to enable the 2030 Vision for Software-Defined Workflows that span multiple cloud infrastructures – which is the way we expect all workflows to ultimately run. In this blog we’ll address one of those gaps and how we’re thinking about systems to close it – namely the issue that “applications need to be able to locate and retrieve assets across all clouds.”
To understand why this is a problem we need to dig a little into the way software applications store files. Why do we need to worry about applications? Because almost all workflow tasks are now conducted by some sort of software system – most creative tasks, even capture devices like cameras are running complex software. The vast majority of this software can access the internet and therefore private and public cloud resources, and yet is still based on legacy file systems from the 1980s. Our challenge with interconnecting all of the applications in the workflow therefore often boils down to how applications are storing their data. If we fix that, we can move on to some more advanced capabilities in creative collaboration.
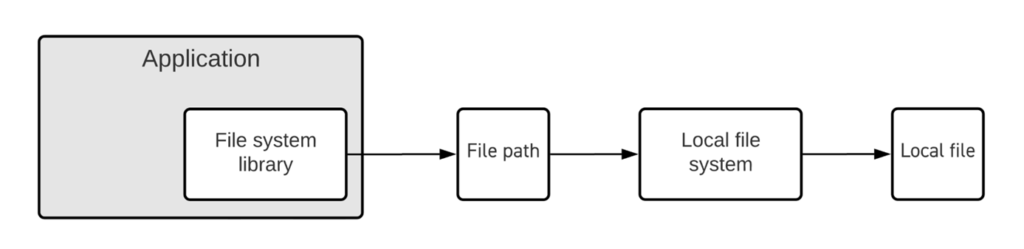
Typically, a software application stores the locations of the files it needs using file paths that indicate where they are stored on a locally accessible file system (like “C:/directory/subdirectory/file_name”). So, for example, an editing application will store the edits being made in an EDL file that is recorded locally (as it’s being created and constantly amended), and the project includes an index with the locations of all the files being manipulated by the editor. Media Asset Management systems also store the locations of files in a database, with similar file paths, like a trail of breadcrumbs, to follow and locate the files. If the files in these file systems move or are not where the application expects them to be when it needs them, then trouble ensues.
Most applications are built this way, and whereas they can be adapted to work on cloud resources (for example by mounting cloud storage to look like a local file system), they are not inherently “cloud aware” and still maintain the names and locations of needed files internally. There are 3 major drawbacks with this approach in collaborative workflows like media creation:
- Locating a shared file may depend on having a common file system environment. E.g., NAS drives must always be mounted with the same drive letter.
- Locating the file is complicated when the file name plus the file path is the guarantee of uniqueness.
- Moving a file (i.e., copy then delete) will break any reference to the file.
We are instead aiming for a cloud foundation which supports a dynamic multi-participant workflow and where:
- Files can move, if necessary, without breaking anything.
- Files don’t have to move, if it’s not necessary.
- If files exist in more than one place, the application can locate the most convenient instantiation.
- Systems, subject to suitable permissions, can locate files wherever they are stored.
- The name of a file is no longer an important consideration in locating it or in understanding its contents or its provenance.[1]
With these objectives in mind, we have been designing and testing a better approach to storing files required for media workflows. We’ll reveal more later in 2022 but for now we wanted to give you a preview of our thinking.
Identifying Identifiers
To find these files anywhere across the cloud, what we need is a label that always and uniquely refers to a file, no matter where it is. This kind of label is usually called an identifier. The label must be “sticky” in that it should always apply to the same file, and only to that file. By switching to an identifier for a file, instead of an absolute file location, we can free up a lot of our legacy workflows and enable our cross-cloud future.
Our future solution therefore needs to operate in this way:
- Participating workflow applications should all refer to files by a common and unique identifier
- Any workflow component can “declare” where a file is (for example, when a file is created)
- Any workflow component can turn a unique identifier into at least one location (using the declaration above)
- Locations are expressed in a common way – by using URLs.
URLs (Uniform Resource Locators) are the foundation of the internet and can be used to describe local file locations (e.g., file://), standard network locations (e.g., http:// or https://), proprietary network locations (e.g., s3://) or even SaaS locations (e.g., box:// used by the web service company Box).
The key to this scenario is a web service that and share that, when presented with a unique identifier, will return the URL location, or locations, of that file. We call this service a resolver, and it’s a relatively simple piece of code that is acting in a similar way to a highly efficient librarian who, when presented with the title and author of a book, can tell you on which shelf and location to go and get it.
Even though MovieLabs created the industry standard Entertainment ID Registry (EIDR), we are not proposing here any universal and unique identifier for each of the elements within all productions going on (that would be a massive undertaking), instead we believe that each production, studio, or facility will run their own identifier registries and resolvers.
We have discussed before why we believe in the importance of splitting the information about a file (for example what type of file it is, what it contains, where it came from, which permission various participants have, its relationships to other files, etc.) from the actual location of the file itself. In many cases applications don’t need to access the file (and therefore won’t need to use the resolver) because they often just need to know information about the file and that can be done via an asset manager. We can envision a future whereby MAMs contain rich information about a file and just the identifier(s) used for it; and utilize a resolver to handle the actual file locations.
With this revised approach we can now see that our application uses an external Resolver service to give it URLs which it can reach out to on a network and retrieve the file(s) that it needs.
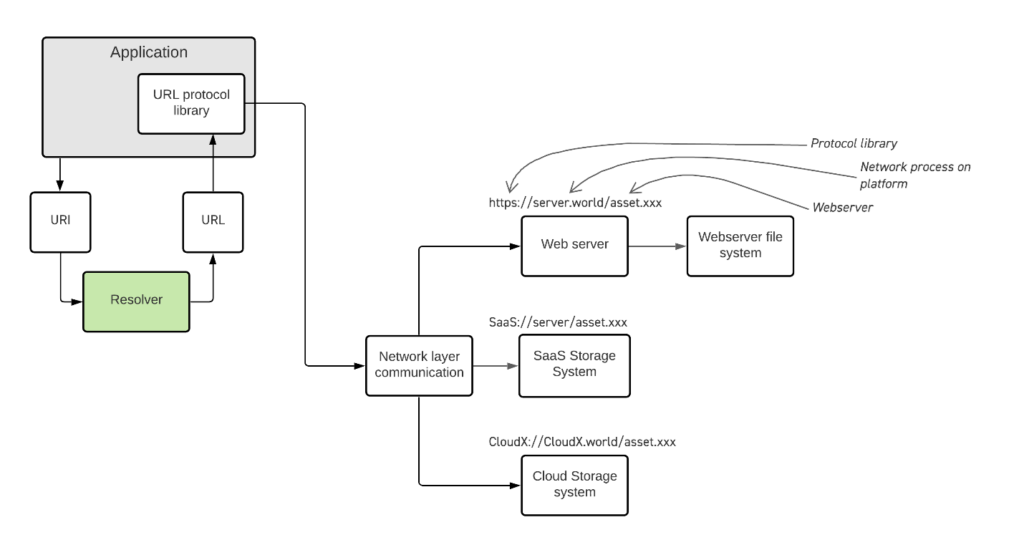
The diagram above shows how the Application now keeps a list of URIs which it can use an external Resolver to turn into a URL for the files it needs. The URL can be resolved by the network into web servers, SaaS systems or directly to cloud storage services. So, in the example of our editing application, now the application maintains sets of unique file identifiers (for the location of the EDL any of the required media elements for the edit) and the resolver points to an actual location, whenever the application needs to find and open those files. The application is otherwise unchanged.
Why use Identifiers and Resolvers, instead of just URLs?
Let us be clear – there are many benefits in simply switching applications to use URLs instead of file paths – that step alone would indeed open up cloud storage and a multitude of SaaS services that would help make our workflows more efficient. However, from the point of view of an application, URLs alone are absolute and therefore do not address our concerns of enabling multiple applications to simultaneously access, move, edit, and change those files. By inserting a resolver in the middle, we can abstract away from the application the need to track where every file is kept and enable more of our objectives including the ability to have multiple locations for each file. Also by using a resolver, if any application needs to move a file it does not need to know or communicate with every other application that also may use that same file, now or in the future. Instead, it simply declares the file’s location to the resolver, knowing that every other participant software application can locate the file, even if that application is added much later in the workflow.
In our editing example above, the “resolver aware” editing application knows that it needs video file “XYZ” for a given shot, but it does not need to “lock” that file and as such it can be simultaneously accessed, referenced, and perhaps edited by other applications. For example, in an extreme scenario, video XYZ could be updated with new VFX elements by a remote VFX artist’s application that seamlessly drops the edited video into the finished shot – without the editor needing to do anything but review and approve, the EDL itself is unchanged and none of the applications involved need to have an awareness of the filing systems used by others.
The resolver concept also has another key advantage; with some additional intelligence, the resolver can return the closest copy of a file to the requesting application. Even though Principle 1 in the 2030 Vision indicates that all files should exist in the cloud with a “single source of truth,” we do also recognize that sometimes files will need to be duplicated to enable speed of performance – for example to reduce the latency of a remote virtual workstation in India for assets that were originally created in London. In those cases the resolver can help as the applications can all share one unique identifier for a file, but the network layer can return the original location for participants in Europe and the location of a cached copy in Asia for a participant requesting access from India.
What needs to happen to enable this scenario?
MovieLabs is busy designing and testing these and other new concepts for enabling seamless multi-cloud interoperability and building out software defined workflows. We’ll be publishing more details of our approach during 2022. Meanwhile there’s an immediate opportunity for all application developers, SaaS providers, hyperscale cloud service companies and others in the broader ecosystem to consider these approaches to interoperable workflows than span infrastructures and the boundaries of specific applications’ scope.
We welcome the input of other companies as we collectively work through these issues and ultimately test and deploy resolver-based systems, feel free to reach out to discuss your thoughts with us.
To ensure you are kept updated with all MovieLabs news and this new architecture be sure to follow us on LinkedIn.
[1] Today such information is often encoded or crammed into a file name or the combination of file name and file path.


